• Introduction à DB2 for i.
(pour un survol incluant Query/400, voyez ce cours)
La base de données IBM i est globale (il n'y a pas de possibilité de créer plusieurs bases indépendantes).
Ce qui s'en rapproche le plus est la notion de bibliothèque. Chaque bibliothèque contient des fichiers base de données autonomes (objets au sens IBM i du mot) :

|
puis vous passerez la commande CRTPF (pseudo compilation). Attention aux paramètres par défaut :
• SIZE(10000 1000 3) indiquent un nombre maxi de
lignes de 13000 (10000, puis 3 incréments de 1000)
• REUSEDLT(*NO), la place des enregistrements
n'est pas récupérée, il faut
régulièrement utiliser RGZPFM
[ avec *YES, les nouvelles lignes sont écrites
physiquement à la place des lignes supprimées]
• MAXMBRS(*NOMAX) ou toute val >
à 1 , autorisant les fichiers multi-membre
Quelques commandes utiles : -------------------------
- DSPFD = description générale
- DSPFFD = liste des champs
- DSPPFM = voir le contenu (non formaté)
- RGZPFM = réorganisation physique des lignes d'une table
- DSPDBR = relations base de données (relations PF <-> LF)
- CPYF = copie d'un fichier Base de données
- STRDFU = utilitaire de maintenance de fichiers & UPDDTA = modifier le contenu DSPDTA = voir le contenu (formaté)
- STRQRY = utilitaire de génération de listes & RUNQRY = lister le contenu (écran ou état)
- STRSQL = SQL interactif (en mode caractères, donc)
Aujourd'hui IBM préconise l'utilisation de SQL (DDL) pour concevoir la base de données.
- Les dernières modifications importantes de SDD datent de la V2R11 (1992 de mémoire...), sont mineures ensuite.
- variables dates/heures , valeur nulle (V2)
- support UNICODE (V5)
- PAGESIZE sur CRTLF (V5)
- Support disques SSD (V6)
- paramètre KEEPINMEM (V7)
- Toutes les autres avancées sont liées à SQL
- Nouveaux types
- Dates/Heures et valeur nulle sont intégrés au SQL de base
- BLOB /CLOB (champs images, PDF)
- OmniFind sait indexer de tels champs
- DATALINK
- champs de type URL avec possibilité de contrôle de l'existence du fichier dans l'IFS.
- NCHAR
- DECFLOAT
- ROWID
- zones auto-incrémentées (AS IDENTITY)
- SEQUENCES
- attribut HIDDEN
- cette colonne est cachée par défaut (SELECT * FROM ... ne la montre pas)
- attribut AS ROW CHANGE TIMESTAMP
- ce TIMESTAMP contient automatiquement date/heure de dernière modification.
- XML
- Intégrité référentielle directement définie avec la table (syntaxe SQL)
- Index EVI pour le BI
- FIELDPROC pour crypter les données
- TRIGGER à la colonne
Attention à la terminologie
Quels sont les avantages de SQL pour la création de tables
- plus de types de données disponibles, nous venons de le voir
- les contraintes sont définies dans le même source, le même langage
- noms plus longs
- 30 c. pour les noms de zone
- 128c pour les noms de table
- lectures plus rapides
En effet, pour des raisons historiques (fichiers décrits en internes) les fichiers créés par SDD ne controlent pas la données insérée.
(il est ainsi possible de stocker "ABC" dans une zone numérique, si vous utilisez des spécifs O en RPG).
En contrepartie, lors de l'utilisation de ces fichier sur un mode externe ou par SQL la donnée est controlée lors de la lecture,
d'où une perte de temps (nous réalisons en général plus d electures que d'écritures sur nos bases)
- Historiquement, journalisation automatique. Désormais nous pouvons utiliser STRJRNLIB
- Possibilité d'utiliser des outils de modélisation (IBM Infosphere Data Architect, Mega Database Builder ou XCASE, par exemple)
Quels sont les avantages de SQL pour la création d'index (vs LF)
- Choix du type :
- B-arbre
- EVI Encoded Vector Index, contenant des infos statistiques
- (des index Bitmap peuvent aussi être utilisés par le moteur, mais de manière temporaire uniquement)
- Pages de 64 K
- Ces index à larges pages sont plus efficaces lors de manipulation de volumes
- les indexs créés par SDD ont des pages de 8k plus efficaces pour recherche une donnée unitaire (CHAIN en RPG)
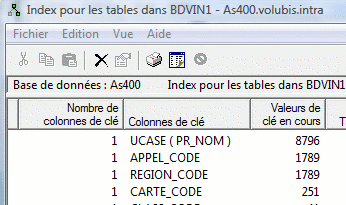
- Depuis la V6, les index peuvent avoir
- une clé composée
CREATE INDEX commandei3 ON COMMANDES ( QTE * PRIX ) ;
- une sélection
where raisoc <> ' ' and nocli > 1 ;

- un format particulier
RCDFMT clientf8 add raisoc ; -- en plus de la clé
Quels sont les avantages de SQL pour la création de vue (vs LF)
- Beaucoup plus de puissance
- une vue peut avoir une jointure interne et les autres externes gauche
- une vue peut retourner des données agrégées (GROUP BY, GROUP BY ROLLUP)
- une vue peut avoir une sélection utilisant toute la puissance du WHERE SQL (CASE par exemple)
- une vue peut utiliser une fonction "maison" c.a.d une UDF
(select nocli, raisoc, dispo(nocli)
from clients) ;- une vue peut utiliser une UDTF (fonction retournant une table à partir de données non BdeD)
(select * FROM TABLE (litrepertoire('/PDF') as PDF);
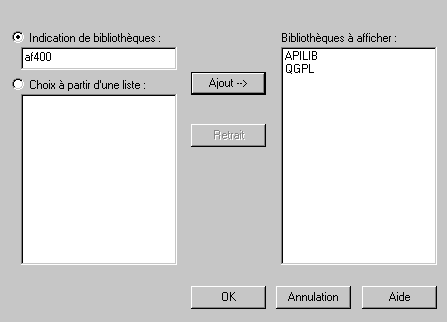
| Affichage par catégorie : |  |
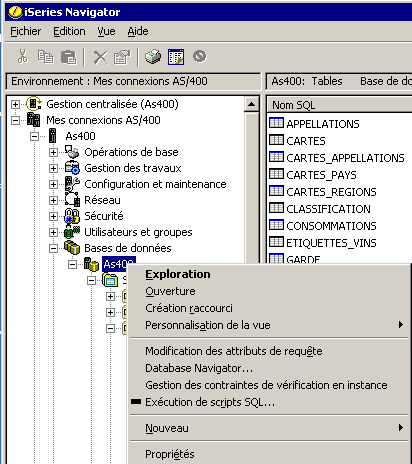
ou avec ACS (IBMi Access Client Solution)
Vous pourrez complètement administrer la base de données
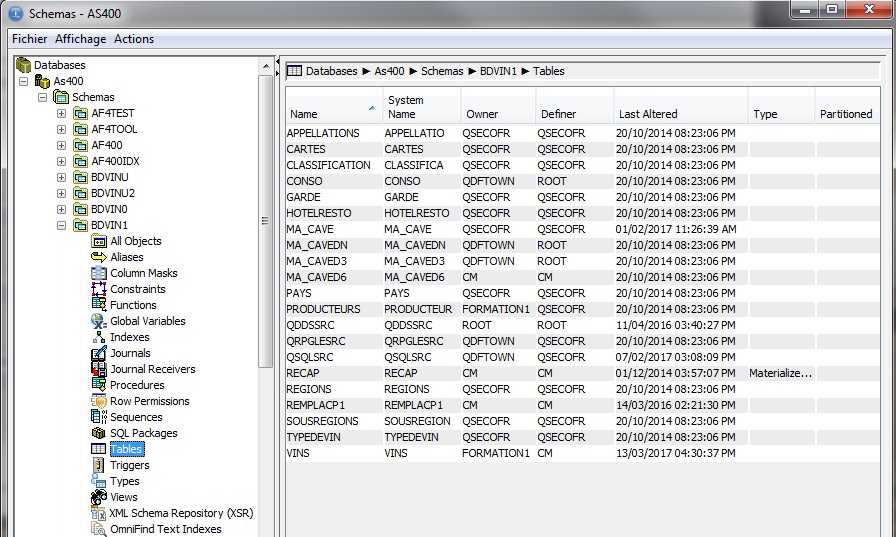
 ->
-> 
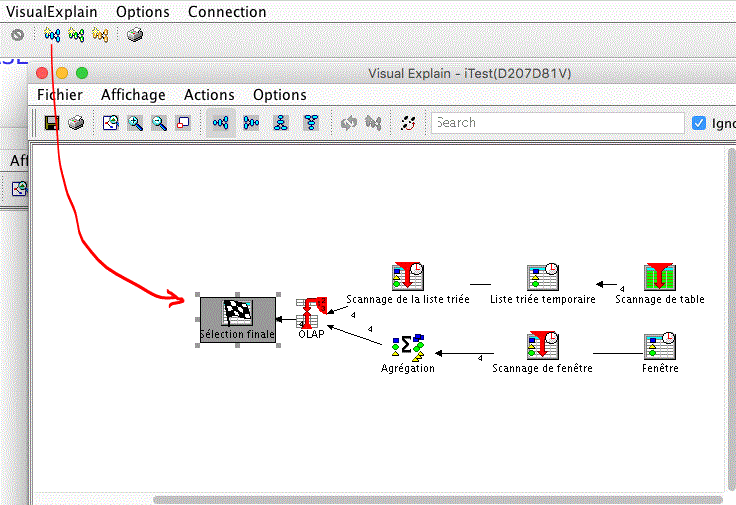
L'affichage se présente comme un affichage de moniteur de performances
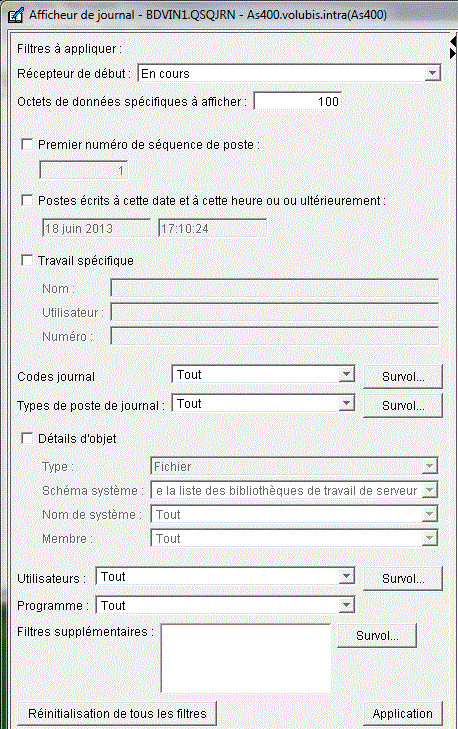




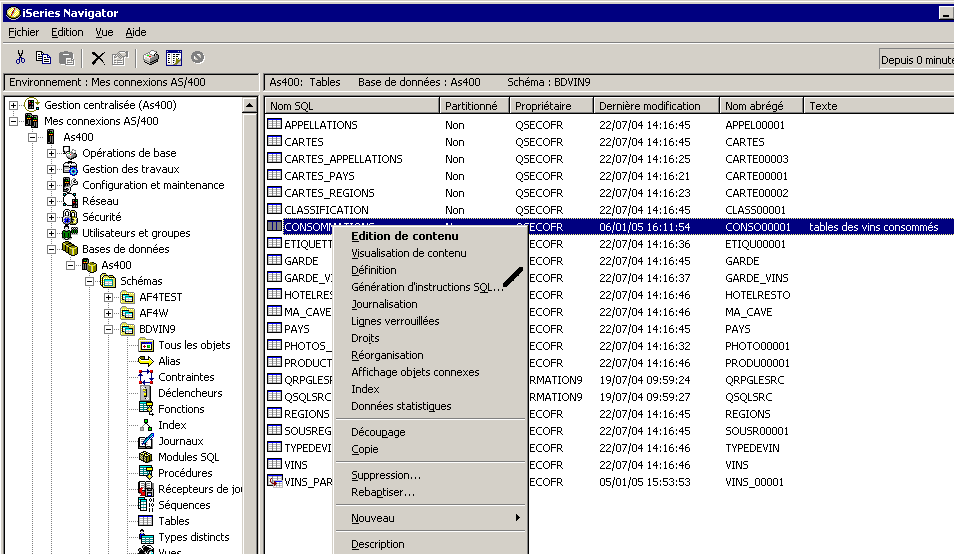
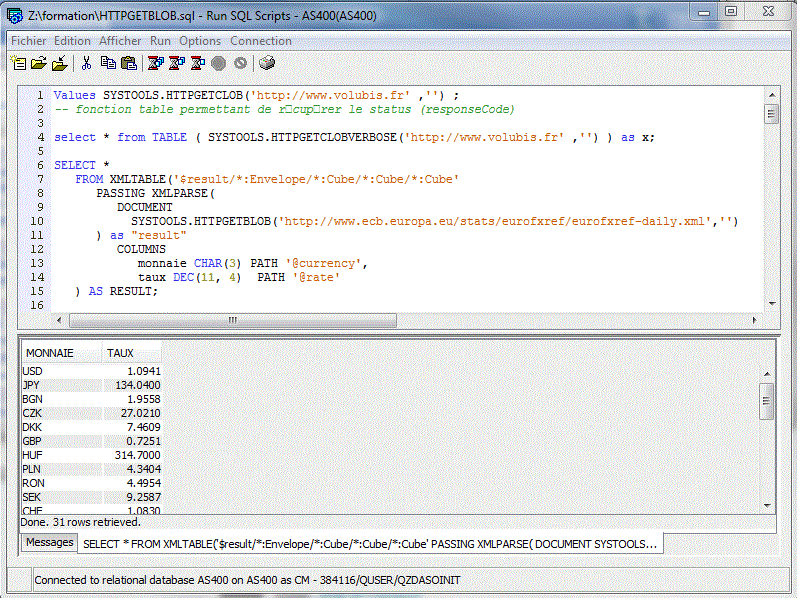
Il sera affiché dans le produit "gestionnaire
de scripts SQL"
Enfin, vous pouvez lancer "à la main" le gestionnaire de scripts
==> Version Windows, sur le nom de votre système, click droit, puis Exécution de scripts SQL.
Sous ACS (version 1.1.5 minimum)

Voyez ensuite notre cours Initiation à la programmation ou bien le cursus RPG.
© AF400 - Volubis