
Le serveur OmniFind est fourni avec la version 7 de IBM i. Il permet une indexation des champs texte, texte enrichi (format .doc ou .pdf, par exemple) et enfin, avec cette nouvelle version 1.2, les champs de type XML.
OmniFind apporte :
Ce produit s'installe par RSTLICPGM 5733OMF, les options 30,33 et 39 de SS1 et java (JV1) sont des pré-requis.
L'installation doit vous créer un serveur de texte avec l'ID n° 1 (cela créé un répertoire /QOpenSys/QIBM/ProdData/TextSearch/server1)
La requête suivante donne la liste des serveurs :
SELECT SERVERID,SERVERPORT,SERVERSTATUS,SERVERPATH FROM QSYS2.SYSTEXTSERVERS
(ServerStatus à 0 indique un serveur actif, 1 inactif)
Ainsi que System i navigator
le serveur se démarre avec cette même interface ou IBM Navigator Director
ou avec les procédures cataloguées suivantes
Vous pouvez créer un index OmniFind sur les types de donnée suivants :
les données peuvent être stockées en texte simple, HTML, XML, ou un format enrichi. Elles seront transformées en UNICODE 1208 avant d'être indexées, donc pas de job en CCSID(65535).Ce ne sont pas des index traditionnels DB2 (pas d'objet, donc pas de SAVOBJ) , ils ne sont pas maintenus temps réel et n'ont d'existence que dans le cadre du serveur OmniFind.
Les index sont enregistrés dans SYSTXTINDX de QSYS2, trois triggers sont ajoutés à la table indexée qui stockent les mises à jour dans une table temporaire, dite table de transfert, crée elle aussi à cette occasion (toujours dans QSYS2).
Création d'un Index
CALL SYSPROCS.SYSTS_CREATE
Paramètres
- Nom de l'index VARCHAR(128)
- Schéma (bibliothèque) VARCHAR(128)
- Source, sous la forme
- schéma.table(colonne) référence une zone du fichier, à indexer.
- schéma.table(schéma.fonction(colonne) ) référence une fonction à lancer sur une des zones de la table dont il faut indexer le résultat
On pourrait ainsi imaginer une fonction qui lise un fichier dans l'IFS et en retourne le contenu afin d'utiliser OmniFind pour indexer des fichiers stream associés à des éléments base de donnée.
- Options
- CCSID un n° de CCSID
- LANGUAGE un code langage (fr_FR ou en_US)
- FORMAT
- TEXT
- HTML
- XML
- INSO qui permet une reconnaissance automatique des formats Lotus, Word, Excel, Pps, Html, PDF, OpenOffice et RTF.
- UPDATE FREQUENCY
- NONE
- D( )
- * tous les jours
- 0 à 6 : le N° du jour de la semaine de mise à jour
- H( )
- * toutes les heures
- 0 à 23 : heure de mise à jour
- M( )
- * toutes les 5 minutes
- 0 à 59 : minutes de mise à jour
par exemple UPDATE FREQUENCY D(*) H(*) M(0 , 30) demande une mise à jour toutes les demi-heures
- On peut aussi utiliser un format chronologique plus compliqué à manipuler
- UPDATE MINIMUM
- nombre de mise à jour avant UPDATE de l'index tel que planifié par UPDATE FREQUENCY
- INDEX CONFIGURATION( )
- IGNOREEMPTYDOCS
- 0 les documents vide (colonne nulle) sont répercutés dans l'index
- 1 les documents vides ne sont pas répercutés dans l'index
- KEYCOLUMN
- nom de la zone clé à utiliser lors des mise à jour d'index, si non précisé la zone ROWID ou la clé primaire sera utilisée
- UPDATEAUTOCOMMIT
- indiquez un nombre de ligne à mettre à jour lors de la mise à jour de l'index avant de commiter
- 0, le commit n'a lieu qu'une seule fois en fin de mise à jour de l'index
- COMMENT
- indiquez un commentaire de 512c. maxi
(les valeurs par défaut des options sont stockées dans SYSTEXTDEFAULTS)
Exemple :
CALL SYSPROC.SYSTS_CREATE('BDVIN1', 'PRODUCTEURS_IX', 'BDVIN1.PRODUCTEURS(PR_AVIS)', 'CCSID 1208 LANGUAGE fr_FR FORMAT TEXT UPDATE FREQUENCY NONE UPDATE MINIMUM 1 INDEX CONFIGURATION(IGNOREEMPTYDOCS 1 , UPDATEAUTOCOMMIT 100)');
Une ligne est ajoutée dans SYSTEXTINDEXES (Nom système : SYSTXTINDX)la table de transfert est créé dans QSYS2 (son nom est précisé dans STAGINGTABLENAME), les trois triggers sont ajoutés à la table indexée afin d'écrire dans la table de transfert
un répertoire est créé dans l'IFS (répertoire /QOpenSys/QIBM/ProdData/TextSearch/server1/config/collections)
son nom est indiqué par COLLECTIONNAME (par exemple 0_1_3_2010_09_28_17_10_36_131543, pour l'index 3 créé en septembre 2010)Une vue est créé portant le nom de l'index (PRODUCTEURS_IX) dans la bibliothèque indiquée. C'est le seul objet pouvant être sauvegardé par SAVOBJ.SAVLIB.
La restauration de la vue, recréé l'index de recherche OmniFind (sans les données) et relance l'indexation.
Ensuite, il vous lancer la procédure de mise à jour (l'index est créé vide par SYSTS_CREATE) :
CALL SYSPROCS.SYSTS_UPDATE
- Schéma
- Nom de l'index
- Option (facultative)
- USING UPDATE MINIUM
- nombre de mise à jour minimum dans la table de transfert pour faire la mise à jour de l'index.
l'index est alors créé dans le répertoire de la collection (la création prend au moins 3 à 5 fois le temps de création d'un index "normal")
-> Pour détruire l'index
CALL SYSPROCS.SYSTS_DROP
- Schéma
- Nom de l'index
-> Pour modifier les caractéristiques de l'index
CALL SYSPROCS.SYSTS_ALTER
- Schéma
- Nom de l'index
- Options
- toutes les options de la procédure SYSTS_CREATE
- RENAME FUNCTION
- pour renommer la fonction, si ce n'est pas une colonne qui est indexée.
Deux fonctions sont à votre disposition :
Exemple :
WHERE contains(pr_avis,'excellent') = 1
Que mettre dans une expression de type texte
Exemple :
contains(pr_avis, 'chateau AND (pomerol OR lafite)') = 1 ;
trouve les lignes contenant chateau ou château ou châteaux puis, soit pomerol, soit lafite.
On peut même créer un dictionnaire de synonymes personnel en créant un fichier XML
Exemple :
<synonymgroups version="1.0">
<synonymgroup>
<synonym>vin</synonym>
<synonym>pinard</synonym>
<synonym>picrate</synonym>
<synonym>nectar</synonym>
</synonymgroup>
<synonymgroup>
<synonym>syrah</synonym>
<synonym>schiraz</synonym>
</synonymgroup>
</synonymgroups>
puis en passant la commande (sous QSH)
-synonymFile <chemin du fichier XML>
-collectionName <nom de la collection>
-replace <[true|false]>
-configPath <chemin absolu du dossier de config.>
Exemple
> cd /QopenSys/QIBM/ProdData/TextSearch/server1/bin > synonymTool.sh importSynonym
-synonymFile /temp/vin_synonyme.xml
-collectionName 0_1_3_2010_09_28_17_10_36_131543 -replace false
-configPath /QopenSys/QIBM/ProdData/TextSearch/server1/config
IQQD0084I The request was successfully executed.
$
contains(pr_avis, 'pinard')= 1 Donne 1 (pinard est le nom d'un producteur de Cognac) select count(*) FROM bdvin1/producteurs WHERE
contains(pr_avis, 'pinard', 'SYNONYM=ON')= 1 Donne 606
Recherche XML
La syntaxe des recherches XML utilise un sous-ensemble du langage W3 XPath
sous la forme CONTAINS(nom_colonne, '@xmlxp: ' 'expression_requête_Xpath' ' ')
le deuxième paramètre de la fonction CONTAINS est une chaîne donc entre quote ('), l'expression XPath étant elle même entre quotes il faut doubler ces dernières
vous devez indiquer un chemin dans l'arborescence XML :
Expression XPath Signifie / sélectionne le nœud, dit root element, qui englobe tout le document sauf <?xml version="1.0"?> // sélectionne tous les noeuds . sélectionne le nœud en cours /customerinfo sélectionne le nœud "customerinfo" //city sélectionne tous les éléments "city" du document où qu'ils soient /customerinfo/name sélectionne l'unique élément "name" fils de "customerinfo" puis, éventuellement, un Predicat (un test) devant être vrai, toujours entre crochets [ et ]
Prédicat Signifie //phone[. = "xxx"] sélectionne tous les éléments "phone" du document (où qu'ils soient), ayant une valeur égale à xxx //phone[@type = "work"] sélectionne tous les éléments "phone" du document, ayant un attribut "type" dont la valeur est "work" Pour les valeurs :
- Numerique, saisissez tel que '//quantite[. > 12000]'
- Alpha, saisissez entre guillemets '//phone[. = "02.40.30.00.70"]'
- Date, xs:date ou xs:DateTime, par exemple utilisez '/Article[@DateCrt > xs:date("2010-10-05")]'
- la requête XPath peut elle même contenir une recherche textuelle avec contains ou exclude, comme
'/Article[libart contains("piece AND rechange")]'Exemples :
'<customerinfo xmlns="http://posample.org" Cid="1000">
<name>Kathy Smith</name>
<addr country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>') INSERT INTO Customer (Cid, Info) VALUES (1002,
'<customerinfo xmlns="http://posample.org" Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>') INSERT INTO Customer (Cid, Info) VALUES (1003,
'<customerinfo xmlns="http://posample.org" Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-2937</phone>
</customerinfo>')
SELECT * from posample/customer
where contains(info, '@xmlxp:''//name'' ') = 1 ....1....+.
CID
1.000 1.002 1.003
SELECT * from posample/customer
where contains(info, '@xmlxp:''//phone[. = "416-555-1358"]'' ')=1
....1....+.
CID
1.000
SELECT * from posample/customer
where contains(info,'@xmlxp:''//phone[. contains("905") ]'' ') = 1 ....1....+.
CID
1.002
1.003
SELECT * from posample/customer
where contains(info,'@xmlxp:''/customerinfo[phone = "416-555-1358"]'' ')=1
....1....+.
CID
1.000
La PTF SI40272 ainsi que le dernier niveau de GROUP PTF pour DB2 (level 9) apporte à Omnifind, deux fonctions supplémentaires
Vous devez d'abord créer une collection pour stocker ces informations, cela va créer une bibliothèque, contenant
- des tables contenant des informations sur les données à indexer
- des tables contenant des informations sur les paramètres d'indexation
- des procédures cataloguées de recherche et d'administration
CALL SYSPROC/SYSTS_CRTCOL('OMNI_COL') -- nous utiliserons ce nom de collection pour le reste de nos exemplesvous pouvez fournir des options d'indexation , comme CALL SYSPROC.SYSTS_CRTCOL(‘OMNI_COL’,‘UPDATE FREQUENCEY D(*) H(0) M(0)’)
ou CALL SYSPROC.SYSTS_CRTCOL(‘OMNI_COL’,‘FORMAT INSO’) -- si les fichiers IFS sont de type Word, PDF, etc...
Ensuite vous devez accorder des droits à la procédure cataloguée SEARCH qui vient d'être créé
SET CURRENT SCHEMA OMNI_COL
GRANT EXECUTE ON PROCEDURE SEARCH(VARCHAR) TO QPGMR
comment ajouter des objets à l'index, toujours par procédure cataloguée
Il faut toujours commencer par définir la collection dans le chemin de recherche des procédures cataloguées
SET CURRENT PATH OMNI_COL
- SPOOL
CALL ADD_SPLF_OBJECT_SET(‘QGPL’, ‘QPRINT’) -- par OUTQ
ou bien CALL ADD_SPLF_OBJECT_SET(‘’, ‘’ , 'QPGMR') -- par propriétaire
version complète (un paramètre à blanc n'est pas un critère)
CALL ADD_SPLF_OBJECT_SET(‘ ’ -- bibliothèque OUTQ
‘ ’ -- OUTQ ‘ ’ -- Propriétaire ‘ ’ -- nom du JOB ‘ ’ -- profil du JOB ‘ ' -- N° du JOB ‘ ’) -- USRDTA ‘2011-06-01T00:00:00’ -- date/heure de début '2011-06-30T23:59:59' -- date/heure de fin )- IFS
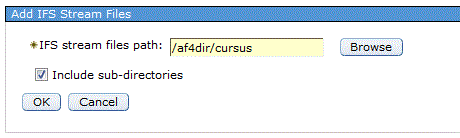
CALL ADD_IFS_STMF_OBJECT_SET(‘/home/mesfichiers’)
Remarques : -> le paramètre doit être un nom de répertoire -> ne peut pas contenir de caractères génériques (*) -> les liens symboliques ne sont pas traités -> les sous-répertoires ne sont pas traitésEnsuite vous devez rafraîchir l'index OmniFInd pour indexer réellement
CALL UPDATE
enfin vous pouvez faire des recherches, par CALL SEARCH('mot-recherché')
cela retourne un "result set" structuré comme suit :
Exemple
structure de la zone OBJECTINFOR
Autres procédures
QUERY_OBJECT_SET
Retourne la liste des objets indexés
GET_OBJECT_STATUS
retourne le status d'un objet
- 0 indexé
- 10 en cours d'indexation
- 20 objet modifié depuis l'indexation
- 30 objet indexé, mais avec un Warning
- 40 indexation en erreur
GET_OBJECTS_NOT_INDEXED
retourne la liste des objets non indexésSTATUS
retourne le status du serveurSYSTS_DRPCOL
détruit une collection
Pour de plus amples détails, voyez la documentation http://www-03.ibm.com/systems/resources/systems_power_ibmi_omnifind_extensions_user_guide.pdf
Dernière nouveauté (SF99701 , level 18)
-> Possibilité d'indexer des membres sources
CALL ADD_SRCPF_OBJECT_SET(
‘AF400 ’ -- bibliothèque
‘QCLSRC ’ -- fichier source
)
Attention, seules les collections créées après cette PTF contiennent la procèdure. Pour créer la procédure dans les collections existantes passer la commande suivante : CALL QDBTSLIB/QDBTSUPGRD; -- concernent toutes les collections Omnifind
CALL QDBTSLIB/QDBTSUPGRD ('OMNI_COL'); -- concernent uniqument cette collection |
cela retourne un "result set" structuré comme pour les spools et les fichiers IFS :
- OBJTYPE CHAR(10) ->: *SRCPF
- OBJATTR CHAR(10) ->*MBR
- CONTAINING_OBJECT_LIB CHAR(10)
- CONTAINING_OBJECT_NAME CHAR(10)
- OBJECTINFOR XML
- MODIFY_TIME TIMESTAMP
- SCORE DOUBLE
Exemple

Structure de la zone OBJECTINFOR
Un même index, peut indexer des spools, des fichiers streams et des membres sources
Pour arrêter l'indexation, retrouver le SETID par QUERY_OBJECT_SET
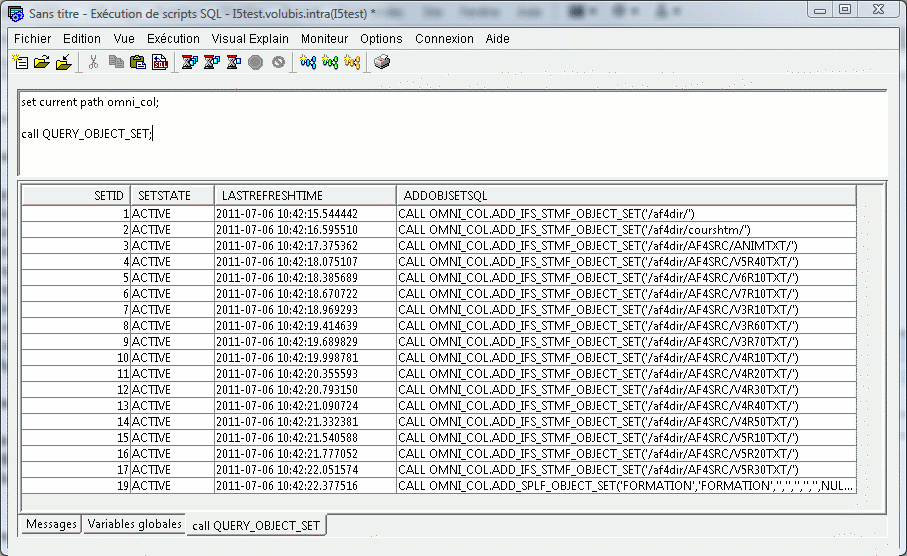
puis,
La PTF SI48982 propose une nouvelle procédure pour OmniFind lors de l'indexation de fichiers de l'IFS : ADD_IFS_STMF_OBJECT_SET_WITH_SUBDIR
permettant lors de l'ajout d'un répertoire à un Index Omnifind, d'ajouter automatiquement les sous répertoires
Après l'installation de la PTF, là aussi, il faut passer CALL QDBTSLIB/QDBTSUPGRD.
Cette option se retrouve
dans Navigator for i.

L'option Create collection propose un interface à la procédure SYSTS_CRTCOL

L'option Collection List, liste les index Omnifind créés par
SYSTS_CRTCOL
 , properties permettant une maintenance des objets indéxés
, properties permettant une maintenance des objets indéxés
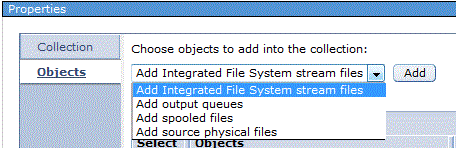 ->
-> 
Enfin Search permet une recherche dans l'index

Résultat 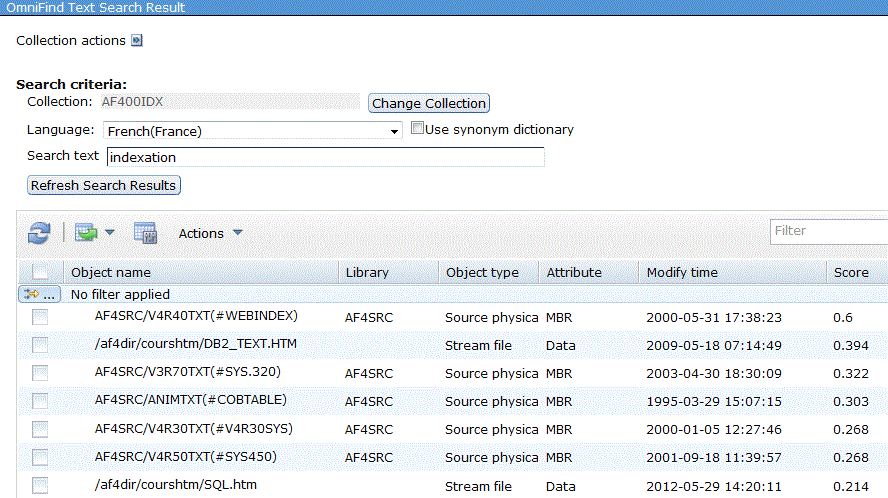
- Cette version peut être installée alors que vous avez une version 1.2, une migration sera faite.
- Cette version contient bien sûr, les fonctionnalités d'indexation apportées en V1R2 , via PTF
Autre nouveautés :
SELECT COLLECTIONNAME, SERVERID FROM TABLE(QDBTSLIB.QDBTS_LISTINXSTS()) AS T |
Liens
Accès à la documentation officielle
V1R2 : http://www-01.ibm.com/support/knowledgecenter/ssw_ibm_i_71/rzash/rzash.pdf
V1R3 : http://www-01.ibm.com/support/knowledgecenter/ssw_ibm_i_72/rzash/rzashpdf.pdf







