Intégration du SQL au FreeFormRPG
Il vous faut être, si possible, à jour quant à la syntaxe SQL
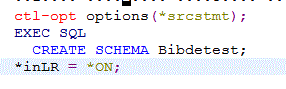
Embedded SQL
Il s'agit d'embarquer du SQL à l'intérieur du langage RPG qui est dit langage Hôte (Host)Le type de source doit être SQLRPGLE.
il y a un pré-compilateur qui s'occupe des ordres SQL (il doit donc les reconnaitre) puis lance la compilateur RPG s'il n'y a pas d'erreur
un ordre SQL est encadré de EXEC SQL et de ; ->
un ordre SQL à la fois
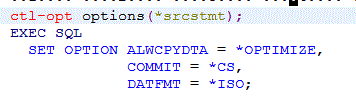
Des paramètres d'exécution peuvent être indiqués par SET OPTION (ce doit être la première instruction SQL)
- ALWCPYDTA = copie des données admise ?
- *NO une copie des données n'est pas admise
- *YES une copie est admise quand cela est nécessaire
- *OPTIMIZE, à chaque fois que cela permet d'aller plus vite
- COMMIT = niveau de COMMIT (voir CRTSQLRPGI en fin de cours)
- *NONE hors contrôle de validation
- *CHG verrouillage des lignes modifiées
- *CS idem *CHG + une ligne lue (test de disponibilité)
- *ALL verrouillage de toutes les lignes lues,modifiées, insérées
- CONACC = concurrence d'accès (pour *CS)
- *DFT mode de fonctionnement par défaut (cf QAQQINI)
- *WAIT Attendre (60s) que l'enregistrement se libère
- *CURCMT travailler avec la dernière version validée
- DATFMT = *ISO | *EUR | *DMY ...
- DATSEP = (un séparateur)
- TIMFMT = *ISO | *EUR | *HMS ...
- TIMSEP = (un séparateur)
- DECPNT = (marque décimale)
- *PERIOD : le point
- *COMMA : la virgule
- *SYSVAL : voir la val. système QDECFMT
- *JOB : voir le job
- USRPRF = *USER | *OWNER | *NAMING
profil de référence pour les droits
- *USER, l'utilisateur ayant lancé le pgm
- *OWNER le propriétaire du pgm
- *NAMING si convention *SQL = *OWNER, sinon *USER
- DYNUSRPRF = *USER | *OWNER
même notion pour les instructions dynamiques
- NAMING = *SYS | *SQL
convention d'appellation
- *SYS le qualifiant est le / , sans schéma *LIBL est utilisée
- *SQL la qualifiant est le . , sans schéma USER (le nom de l'utilisateur) est utilisé
- DFTRDBCOL = nom RDB (enregistré par WRKRDBDIRE)
connexion automatique à une base éloignée
- SRTSEQ séquence de classement
- *HEX l'EBCDIC fait référence
- *LANGIDUNQ tenir compte de la langue, mais é <> ê
- *LANGIDSHR tenir compte de la langue et e=é=è=ê
- LANGID code langage (FR par exemple)
- SQLCA (voir ci-dessous)
- *YES, SQLCA est mis à jour à chaque instruction
- *NO, SQLCA n'est pas mis à jour, utilisez GET DIAGNOSTIC
- EXTIND
- *YES, vous pourrez utiliser des variables optionnelles sur un UPDATE
- *NO, ce n'est pas possible
Des variables RPG peuvent être utilisées dans les ordres SQL
On parle de variables HOST
Elles sont reconnues car elles commencent par : dans le SQL
Vous pouvez avoir un retour sur chaque ordre SQL
Avec la structure générée automatiquement par le précompilateur : SQLCA
en RPG4, la même zone est définie 2 fois :
- une fois en nom sur 6 lettres (pour compatibilité avec RPG III)
- une fois en nom long pour être à la norme (ISO)
DCL-DS SQLCA;
SQLCAID CHAR(8) INZ(X'0000000000000000');
SQLAID CHAR(8) OVERLAY(SQLCAID);
SQLCABC INT(10);
SQLABC BINDEC(9) OVERLAY(SQLCABC);
SQLCODE INT(10);
SQLCOD BINDEC(9) OVERLAY(SQLCODE);
SQLERRML INT(5);
SQLERL BINDEC(4) OVERLAY(SQLERRML);
SQLERRMC CHAR(70);
SQLERM CHAR(70) OVERLAY(SQLERRMC);
SQLERRP CHAR(8);
SQLERP CHAR(8) OVERLAY(SQLERRP);
SQLERR CHAR(24);
SQLER1 BINDEC(9) OVERLAY(SQLERR:*NEXT);
SQLER2 BINDEC(9) OVERLAY(SQLERR:*NEXT);
SQLER3 BINDEC(9) OVERLAY(SQLERR:*NEXT);
SQLER4 BINDEC(9) OVERLAY(SQLERR:*NEXT);
SQLER5 BINDEC(9) OVERLAY(SQLERR:*NEXT);
SQLER6 BINDEC(9) OVERLAY(SQLERR:*NEXT);
SQLERRD INT(10) DIM(6) OVERLAY(SQLERR);
SQLWRN CHAR(11);
SQLWN0 CHAR(1) OVERLAY(SQLWRN:*NEXT);
SQLWN1 CHAR(1) OVERLAY(SQLWRN:*NEXT);
SQLWN2 CHAR(1) OVERLAY(SQLWRN:*NEXT);
SQLWN3 CHAR(1) OVERLAY(SQLWRN:*NEXT);
SQLWN4 CHAR(1) OVERLAY(SQLWRN:*NEXT);
SQLWN5 CHAR(1) OVERLAY(SQLWRN:*NEXT);
SQLWN6 CHAR(1) OVERLAY(SQLWRN:*NEXT);
SQLWN7 CHAR(1) OVERLAY(SQLWRN:*NEXT);
SQLWN8 CHAR(1) OVERLAY(SQLWRN:*NEXT);
SQLWN9 CHAR(1) OVERLAY(SQLWRN:*NEXT);
SQLWNA CHAR(1) OVERLAY(SQLWRN:*NEXT);
SQLWARN CHAR(1) DIM(11) OVERLAY(SQLWRN);
SQLSTATE CHAR(5);
SQLSTT CHAR(5) OVERLAY(SQLSTATE);
END-DS SQLCA;
Variables de SQLCA importantes :
- SQLCODE ou SQLCOD
- 0 = pas d'erreur
- >0 = ordre exécuté mais avec erreur (ex +100 = no record found)
- <0 = erreur, ordre non exécuté
- SQLERRMC Texte du message SQL d'erreur si SQLCODE<0
- SQLERRML longueur significative de SQLERRMC
- SQLERRD ou SQLERR (ERREUR) 6 fois 4 octets binaires
- ==> en RPG IV, un tableau DIM(6)
- ==> en RPG III, aussi 6 zones de SQLER1 à SQLER6
- SQLERRD(1) ou SQLER1 contient le N° message CPF (erreur) si SQLCODE < à 0.
- SQLERRD(2) ou SQLER2 contient le N° message CPD (diagnostique)
- SQLERRD(3) ou SQLER3 donne le nb de lignes affectées par un ordre UPDATE,DELETE, ou INSERT
- SQLWARN ou SQLWRN (WARNING) 8 indications alpha contenant ' ' ou 'W'
Un état SQLSTATE peut correspondre à plusieurs SQLCODE , le lien suivant peut vous aider à vous y retrouver :
http://www-01.ibm.com/support/knowledgecenter/ssw_ibm_i_72/rzas2/rzas2finder.htm
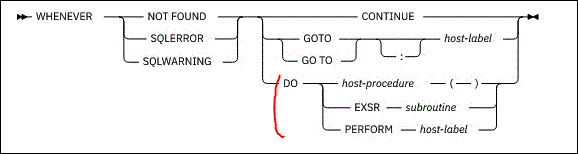
Historiquement vous pouviez utiliser le code WHENEVER pour gérer les erreurs, mais celui ci etait basé sur GOTO
I-NOT FOUND---I
WHENEVER ----I-SQLERROR----I---->-GOTO--(label)
I-SQLWARNING--I
Depuis la TR3 (7.4) TR9(7.3) vous pouvez exécuter une procédure ou un sous/pgm
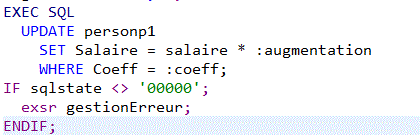
ou bien , testez simplement SQLCODE/SQLSTATE
Vous pouvez aussi retrouver certaines informations, plus clairement peut-être, par :GET DIAGNOSTICS
Exec SQL GET DIAGNOSTICS CONDITION 1 Message = MESSAGE_TEXT ;
Exec SQL GET DIAGNOSTICS CONDITION 1 Etat = DB2_RETURNED_SQLSTATE | DB2_RETURNED_SQLCODE;
Exec SQL CALL procedure;
Exec SQL GET DIAGNOSTICS valretour = RETURN_STATUS;
Exec SQL DELETE From fichier Where ... ;
Exec SQL GET DIAGNOSTICS nbrdelignes = ROW_COUNT;
SQL STATIQUE
Insert
(NUMSTG, NOM, PRENOM, AGENCE)
VALUES(:NOSTAG, :NMSTG, :PRESTG, :AGENCE);Update
EXEC SQL UPDATE SQLDB/STGTBL SET NOM = :NMSTG, PRENOM = :PRESTG WHERE NUMSTG = :NOSTAG;ou bien
Delete
Select
(cette syntaxe n'est valide que si l'ordre ne permet de retrouver qu'UNE LIGNE à la fois)
EXEC SQL SELECT NOM, PRENOM, AGENCE INTO :NMSTG, :PRESTG, :AGENCE
FROM SQLDB/STGTBL
WHERE NUMSTG = :NOSTAG;
ou bien
FROM SQLDB/STGTBL
WHERE NUMSTG = :NOSTAG;
ou bien
DCL-DS DSstagiaire EXTNAME('STGTBL') END-DS; EXEC SQL SELECT * INTO :DSstagiaire
FROM SQLDB/STGTBL
WHERE NUMSTG = :NOSTAG;ou encore
DCL-DS DSstagiaire EXTNAME('STGTBL') END-DS; DCL-DS DSagence EXTNAME('AGETBL') END-DS; EXEC SQL SELECT S.*, A.* INTO :DSstagiaire , :DSagence
FROM SQLDB/STGTBL S join SQLDB/AGETBL A
ON S.AGENCE = A.AGENCE
WHERE NUMSTG = :NOSTAG;
Valeur NulleATTENTION, cette syntaxe suppose que les variables lues n'acceptent pas la valeur nulle.
(en cas de valeur nulle vous recevrez un message SQL0305 et SQLCOD <>0)
Pour gérer la valeur nulle, écrivez :
// variables indicateurs DCL-S nmstgi int(5); DCL-S prestgi int(5); DCL-S agencei int(5);
EXEC SQL SELECT NOM, PRENOM, AGENCE INTO :NMSTG:NMSTGi, :PRESTG:PRESTGi, :AGENCE:AGENCEi
FROM SQLDB/STGTBL
WHERE NUMSTG = :NOSTAG;ou bien
// variables indicateurs
DCL-S WstagiaireI INT(5) DIM(3);
EXEC SQL SELECT NOM, PRENOM, AGENCE INTO :DSstagiaire:WstagiaireI
FROM SQLDB/STGTBL
WHERE NUMSTG = :NOSTAG;
ou encore
// variables indicateurs
DCL-DS DSstagiaireI; nmstgi int(5); presti int(5); agencei int(5); WstagiairesI INT(5) DIM(3) POS(1); END-DS;
EXEC SQL SELECT NOM, PRENOM, AGENCE INTO :DSstagiaire:WstagiaireI
FROM SQLDB/STGTBL
WHERE NUMSTG = :NOSTAG;NMSTGi, PRESTGi et AGENCEi étant des variables binaires sur 2 octets (5,0 Integer)
Chaque variable binaire (SQL parle d'indicateur HOST) pouvant contenir :
- 0 : la variable associée à un contenu significatif
- > 0 la variable à un contenu significatif qui a été tronquée, la valeur est la longueur nécessaire
- -1 : la variable contient la valeur nulle
- -2 : SQL a assigné la valeur nulle suite à une erreur de traitement (mapping)
- les mêmes variables indicateur peuvent être utilisées lors d'un UPDATE
EXEC SQL UPDATE SQLDB/STGTBL SET NOM = :NMSTG:NMSTGI, PRENOM = :PRESTG:PRESTGI WHERE NUMSTG = :NOSTAG;Chaque variable binaire pouvant alors contenir :
- 0 : la valeur à assigner est significative
- -1 : la valeur à assigner est la valeur nulle
- -5 : la valeur à assigner est la valeur par défaut (option EXTIND à *YES)
- -7 : faire comme si cette variable n'était pas dans l'ordre UPDATE (option EXTIND à *YES)
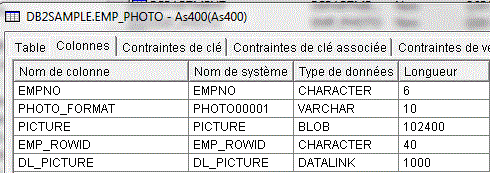
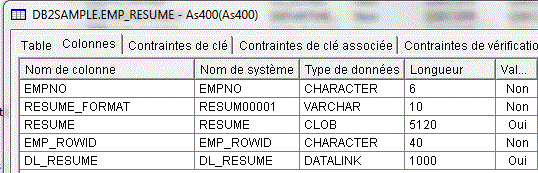
Variables larges (BLOB & CLOB)
Pour lire des variables BLOB (binaires) ou CLOB (caractère)
Exemple avec le résultat de CALL CREATE_SQL_SAMPLE('DB2SAMPLE')
BLOB CLOB
- Déclarer une zone SQLTYPE(BLOB/CLOB :lg)
- elle sera en fait déclarée comme une DS composée de
- zone_data contenant les données brutes du champs BLOB ou CLOB
- zone_len indiquant la longueur de la donnée dans la table
Dcl-s MYCLOB SQLTYPE(CLOB:5000);
EXEC SQL
Select RESUME into :myClob from EMP_RESUME Where ... ;
pos = %scan('recherche' : myClob_data); |
Dcl-s MYCLOB SQLTYPE(CLOB_LOCATOR); EXEC SQL
Select RESUME into :myclob from EMP_RESUME Where ... ;
EXEC SQL
VALUES POSITION('recherche' INTO :MYCLOB) INTO :pos; |
Dcl-s MYBLOB SQLTYPE(BLOB_FILE);
MYBLOB_NAME = '/formation/exemple.gif');
MYBLOB_NL = %len(%trimr(MYBLOB_NAME));
EXEC SQL Select PICTURE into :myblob from EMP_PHOTO Where ... ; |
Exemple : ce pgm retourne une page HTML dans un web service
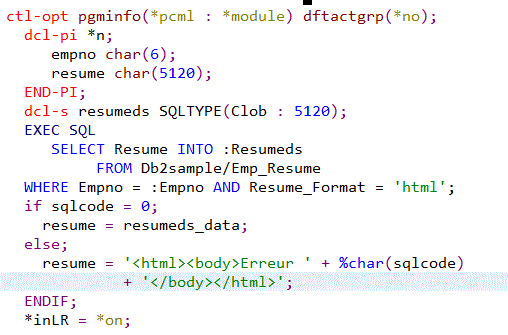

Autre exemple, production d'un flux JSON dans un fichier

Résultat

Curseur
Cette technique permet d'extraire des données multiples (plus d'une ligne)Un curseur est un fichier intermédiaire généré par SQL, rempli par le résultat d'un ordre SELECT et destiné à être lu séquentiellement par l'ordre FETCH.
- Déclaration
SELECT * FROM SQLDB/STGTBL WHERE AGENCE = :AGENCE
[WITH HOLD | WITHOUT HOLD]
[FOR UPDATE OF NMSTG, PRESTG] ;
- Paramètres
- SENSITIVE
le curseur est construit dynamiquement, il reflète les modifications effectuées sur les données non encore lues de la base,
par le pgm en cours ou éventuellement par d'autre, suivant le niveau d'isolation
- INSENSITIVE
le curseur est construit une fois pour toutes avec des données copiées. le pgm est insensible aux modifications effectuées sur la base (y compris par lui). le SELECT ne doit pas contenir FOR UPDATE et ALWCPYDTA doit être différent de *NO- ASENSITIVE
le choix est fait par SQL, le curseur sera sensitif ou pas suivant la requête et le degré d'optimisation (paramètre ALWCPYDTA)
- WITH HOLD, ce curseur n'est pas fermé lors d'un COMMIT
- WITHOUT HOLD, ce curseur est fermé lors du COMMIT, sauf COMMIT HOLD
- FOR UPDATE
permet une modification de la ligne lue (voir ci-dessous)
- Open
- Lecture séquentielle
EXEC SQL FETCH nomcur INTO :DSenreg; ENDDO;les possibilités du INTO sont ici les mêmes que sur un SELECT (y compris val. nulle et Blob)
- Manipulation de la ligne lue (facultatif) si FOR UPDATE
EXEC SQL UPDATE SQLDB/STGTBL
SET PRENOM = :PRESTG
WHERE CURRENT OF nomcur;
EXEC SQL DELETE FROM SQLDB/STGTBL WHERE CURRENT OF nomcur;
- Fermeture
ExempleA partir d'un fichier "Produit", affichage par sous-fichier du nombre de produits et de la quantité moyenne stockée par sous-famille.
Le premier écran demande la famille de produit.
Le deuxième écran affiche le sous-fichier.
* FICHIER ECRAN * --------------- A REF(PRODUIP1) INDARA A R TITRE A 1 2'NOM-PGM' A 1 18' Titre' A DSPATR(UL) A 1 68DATE A EDTCDE(Y) A R F1 A CA03(03 'exit') A OVERLAY ERASE(SFL CLT) A 4 4'FAMILLE DU PRODUIT:' A FAMPRO R Y I 4 25 A 40 ERRMSG('Famille en erreur' 40) A R SFL SFL A SFAPRO R O 7 6 A NBPRO 6 0O 7 13 A MOYEN 9 2O 7 24
A EDTCDE(3) A 7 2'!' A DSPATR(HI) A R CTL SFLCTL(SFL) A OVERLAY A PROTECT A 30 SFLDSP A 30 SFLDSPCTL A N30 SFLCLR A 30 SFLEND A SFLSIZ(0029) A SFLPAG(0028) A SFLLIN(0008) A 6 2'Entète sous-fichier' A DSPATR(UL)
// PROGRAMME RPG // ------------- DCL-F rpgsqle workstn sfile(sfl : rang) indds(indic); // INDARA obligatoire DCL-DS indic; f3 ind pos(3); sfldsp ind pos(30); erreur_famille ind pos(40); END-DS; DCL-S Rang packed(4:0);
EXEC SQL DECLARE C1 CURSOR FOR SELECT SFAPRO, COUNT(*), AVG(QTSPRO) FROM PRODUIP1 WHERE FAMPRO = :FAMPRO GROUP BY SFAPRO; // // Corps du programme (boucle sur image 1) // write TITRE;
exfmt F1; DOw not f3; exsr Principal; exfmt F1; EndDo *inLR = *on; // // Sous pgm traitement d'un produit // Begsr principal;
// Ouverture curseur (le SELECT est exécuté) EXEC SQL OPEN C1; exsr LECTURE; If SQLCOD <> 0; erreur_famille = *on; Else; sfldsp = *off; WRITE CTL; sfldsp = *on;
rang = 0; DOu sqlcod <> 0; rang += 1; write SFL; exsr LECTURE; EndDo;
exfmt CTL; EndIf; // fermeture du curseur // EXEC SQL CLOSE C1; ENDSR; // // LECTURE SEQUENTIELLE DU CURSEUR // BEGSR LECTURE; EXEC SQL FETCH C1 INTO :SFAPRO, :NBPRO, :MOYEN; ENDSR;
- Optimisation
SQL/400 permet de manipuler plusieurs enregistrements à la fois par l'intermédiaire de tableaux de structure:
- en RPG : DATA STRUCTURE à occurrences multiples ou à dimension.
Utilisation:
° INSERT--INTO --nom--------------------VALUES :var-host
! !
! !
!--X------ROWS---!
!-var--!° FETCH--nom-curseur----------------------------INTO :var-host
! !
! !
!-FOR---X------ROWS---!
!-var--!SQLCA:
- SQLERRD(3) = nb d'enregistrements (lus ou insérés)
- SQLERRD(4) = lg enreg
- SQLERRD(5) = indicateur signalant si le dernier poste de la structure a été rempli par FETCH.
En parallèle: Il est possible d'indiquer un facteur d'optimisation
SELECT ------------idem----------------------------------------->
! !
!--OPTIMIZE-FOR x ROWS---------!
(Pour un traitement par sous-fichier , indiquer SFLPAG.)- Curseur flottant
SQL donne la possibilité de se repositionner dans un curseur s'il est déclaré :DECLARE-------idem---------------------------CURSOR--------> ! ! !----------------SCROLL-----! !-DYNAMIQUE-!
- SCROLL seul = en lecture pure
- DYNAMIQUE SCROLL = en mise à jour. (FOR UPDATE).
ce qui permet d'utiliser FETCH de la manière suivante:
FETCH--------------------------------curseur-------> !--NEXT--------------------! !--PRIOR-------------------! !--FIRST-------------------! !--LAST--------------------! !--BEFORE------------------! !--AFTER-------------------! !--CURRENT-----------------! !--RELATIVE----entier------! !-var-host--!SQL DYNAMIQUE
Les ordres SQL (ou certains) ne sont plus compilés par le pré-compilateur mais interprètés et exécutés au moment de l'exécution du programme.
EXECUTE IMMEDIATEexécution dynamique d'un ordre SQL
DCL-S famille PACKED(2:0);
DCL-S fichier CHAR(10) INZ('nomfichier');
//
// mise en place de l'ordre SQL dans requete
//
requete = 'DELETE FROM SQLDB/' +
fichier + ' WHERE FAMPRO = ' + %char(famille);
EXEC SQL
EXECUTE IMMEDIATE :requete;
PREPARE et EXECUTE
Si un ordre SQL dynamique doit être exécuté plusieurs fois il est plus performant de demander à SQL de
l'interpréter une fois par PREPARE et de demander son exécution x fois par EXECUTE.
Il faut donner un nom au résultat du PREPARE et utiliser ce nom dans l'ordre EXECUTE.
Il n'est pas possible d'utiliser des variables "HOST" dans l'ordre PREPARE.
Celles ci seront remplacées par "?" et on utilisera les variables via USING dans EXECUTE
DCL-S famille PACKED(2:0);
DCL-S fichier CHAR(10) INZ('nomfichier');
//
// préparation puis exécution
//
requete = 'DELETE FROM SQLDB/' +
fichier + ' WHERE FAMPRO = ?';
EXEC SQL
PREPARE P1 FROM :requete;
FOR famille = 10 to 25;
EXEC SQL
EXECUTE P1 USING :famille;
ENDFOR;
PREPARE avec un Select
Ceci n'est possible que si les variables extraites par l'ordre SELECT sont TOUJOURS les mêmes.
(Même nombre de variables, même définition)
DCL-PI *N ;
critere char(2);
END-PI;
//
// préparation puis exécution dans le curseur
//
requete = 'Select nocli, raisoc From CLIENTS WHERE DEPART > '
+ critere;
EXEC SQL
PREPARE P1 FROM :requete;
EXEC SQL
DECLARE C1 CURSOR FOR P1;
EXEC SQL
OPEN C1;
// ensuite FETCH et CLOSE comme un curseur "normal"ou bien
DCL-PI *N ;
critere char(2);
END-PI;
//
// préparation puis exécution dans le curseur
//
requete = 'Select nocli, raisoc From CLIENTS WHERE DEPART > ? ';
EXEC SQL
PREPARE P1 FROM :requete;
EXEC SQL
DECLARE C1 CURSOR FOR P1;
EXEC SQL
OPEN C1 Using :critere;Prepare et performances
En général un ordre statique est plus performant, car traité par le pré-compilateur qui créé un plan d'accès (stratégie d'optimisation prévue) stocké dans l'objet *PGM
(on peut le voir par PRTSQLINF)
sauf :
- SELECT.... WHERE NOM LIKE :RECHERCHE
En effet lors de l'utilisation d'un prédicat LIKE le système prévoit l'utilisation d'un Index uniquement en cas de demande du type commence par ('V%')
or, dans ce cas il ne peut pas connaître le contenu qu'aura :RECHERCHE à l'exécution et donc prévoit le pire, un balayage de la table.
Si vous êtes certain de faire des recherches contenant un % uniquement à droite il faut mieux faire un PREPARE où le moteur va optimiser avec la valeur réelle et donc utilisera un index, si possible.
- SELECT .... WHERE NOM LIKE :R1 AND VILLE LIKE :R2 AND REGION LIKE :R3 etc..
Puis vous mettez dans R1 , R2, R3, soit une valeur saisie , soit un % quand l'utilisateur n'a rien saisi.
Là aussi, si vous fabriquez le SELECT dynamiquement, en ne mettant que les critères de recherche réellement utilisés, l'optimiseur pourra mieux utiliser les seuls index nécessaires
Fonctions de Validation/Invalidation
cela permet de mettre en place la notion de transaction (je fais tout ou je ne fais rien, on dit aussi Atomiser)
- on indique le niveau de validation avec lequel on travaille
- sur la commande de compilation (voir plus bas)
- par SET OPTION
- ON valide ou pas, par
- COMMIT, je valide tout ce que j'ai fait dans cette transaction
- Attention, sans HOLD, les curseurs disparaissent lors du COMMIT
- ROLLBACK, j'invalide tout
Ce sont les ordres Commit et Rollback qui définissent la frontière
ils représentent la fin d'une transaction ET le début de la suivante
Sauf à utiliser la notion de SAVEPOINT, permettant de faire plus granulaire :
Cette notion permet de matérialiser des étapes dans une transaction, offrant la possibilité de revenir à un point précis
et non au début de la transaction, en cas de ROLLBACK.
EXEC SQL UPDATE client set dep = 44 where nocli = 1;
EXEC SQL SAVEPOINT MAJ ON ROLLBACK RETAIN CURSORS;
EXEC SQL DELETE FROM COMMANDES where nocli = 999; EXEC SQL DELETE FROM CLIENTS where nocli = 999;
EXEC SQL
SAVEPOINT DLT ON ROLLBACK RETAIN CURSORS ;
EXEC SQL INSERT INTO LOG ... ; IF SQLCODE > 0; // INSERT n'a pas marché EXEC SQL
ROLLBACK TO SAVEPOINT MAJ; // annule les 2 DELETE, pas l'UPDATE ELSE;
EXEC SQL
RELEASE SAVEPOINT ;
ENDIF;ON ROLLBACK RETAIN CURSORS, permet de garder le(les) curseur(s) ouverts
ON ROLLBACK RETAIN LOCKS , permet de garder les verrouillages/ligne
RELEASE SAVEPOINT, libère (détruit) le point de reprise
Procédures stockées
cela permet de demander l'exécution d'un programme sur le serveur ( distant pour ODBC, JDBC) devant réaliser une série d'actions sur la base.
EXEC SQL |
Les paramètres transmis peuvent être :
- Une constante
- Une variable du pgm (:var en RPG)
(par défaut :var est en entrée/sortie avec SQL statique , en entrée (envoyée) avec SQL dynamique)
- NULL
- Une valeur spéciale (CURRENT DATE/TIME/TIMEZONE , SERVER) (USER)
La procédure peut retourner, en plus, une série de valeurs par :
SET RESULT SETS
- WITH RETURN TO
- CALLER , retour du jeu résultat à l'appelant
- CLIENT, retour du jeu résultat au client (ODBC/JDBC)
Ce paramètre est très important dans le cas d'une procédure appelée par un CL (l'appelant) depuis un PC (le client)
- CURSOR un curseur ouvert (seules les lignes non lues sont retournées)
DCL-PI *N ;
critere char(20);
END-PI;
//
// préparation puis exécution dans le curseur
//
requete = 'Select nocli, raisoc From CLIENTS WHERE DEPART > '
+ critere;
EXEC SQL
PREPARE P1 FROM :requete;
EXEC SQL
DECLARE C1 CURSOR FOR P1;
EXEC SQL
OPEN C1;
EXEC SQL
SET RESULT SETS CURSOR C1;
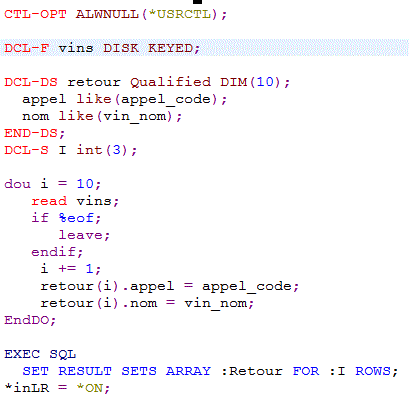
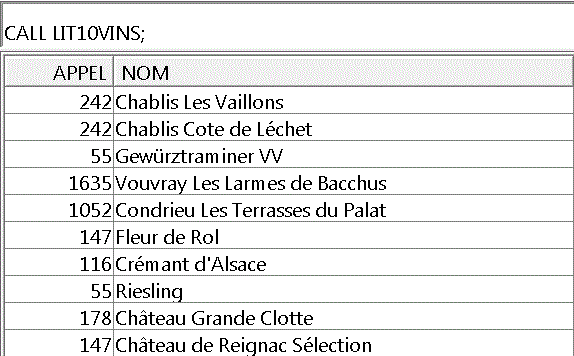
- ARRAY un tableau RPG (DIM ou OCCURS) chargé en mémoire
// lit les 10 premiers vins
DCL-F vins DISK;
DCL-DS retour Qualified DIM(10);
appel like(appel_code);
nom like(vin_nom);
END-DS;
DCL-S I int(3);
dou i = 10;
read vins;
if %eof; leave;
endif;
i += 1;
retour(i).appel = appel_code; retour(i).nom = vin_nom; EndDo;
EXEC SQL
SET RESULT SETS ARRAY :retour FOR :i ROWS;
- Vous devez enregistrer cette procédure (particulièrement s'il y a des paramètres en entrée), par :
- CREATE PROCEDURE
- NOM procédure
- EXTERNAL NAME peut être utilisé pour indiquer un nom système différent
- Liste des paramètres
- Nom
- Type-sql
- CHAR
- DEC
- ....
- utilisation
- IN
- OUT
- INOUT
- LANGUAGE
- RPG
- RPGLE
- C
- COBOL
sans indication l'attribut du programme.
- DYNAMIC RESULT SETS
- indique le nombre de RESULT SETS (inutile quand il n'y en a qu'un)
- PARAMETER STYLE
- GENERAL
un paramètre en entrée dans le pgm, par paramètre de la procédure- GENERAL WITH NULL
un paramètre en entrée + une variable indicateur (va. nulle), par paramètre de la procédure
- SQL
comme GENERAL WITH NULL, plus
- SQLSTATE CHAR(5)
- nom de procédure qualifié CHAR(517)
- nom de procédure simple CHAR(128)
- message en cas d'erreur VARCHAR(1000)
- JAVA
Pour faire référence à une classe Java
- La définition est enregistrée dans les fichiers SYSPROCS et SYSPARMS du catalogue (QSYS2).
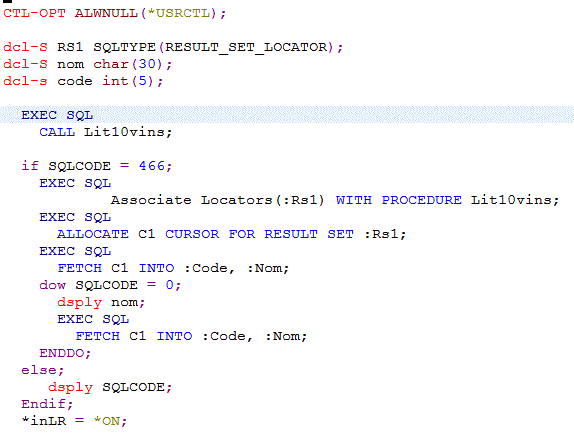
- Depuis la version 7, on peut récupérer en RPG le RESULT SET d'une procédure :
- CALL PROCxxx
- si SQLCODE = +466 // il y a un jeu de résultat retourné
- ASSOCIATE LOCATORS (:RS1) WITH PROCEDURE PROCxxx // :RS1 doit être déclaré SQLTYPE(RESULT_SET_LOCATOR)
- ALLOCATE C1 CURSOR FOR RESULT SET :RS1
Compilation
- CRTSQLRPGI
- COMMIT
- *NONE ou *NC, pas de contrôle de validation.
- (autre valeur) = sous contrôle de validation => erreur si fichier(s) non journalisé(s)
- *CHG ou *UR verrouillage des lignes modifiées jusqu'au COMMIT
- *CS idem *CHG + une ligne lue (test de disponibilité)
- Pour un Select simple, la ligne est verrouillée PUIS libérée (il ne s'agit que de tester sa disponibilité)
- Pour un curseur chaque ligne lue est verrouillée par FETCH jusqu'à la lecture de la ligne suivante.
sauf à préciser KEEP LOCKS à la lecture
- *ALL ou *RS
- Pour un curseur, verrouillage de toutes les lignes lues et modifiées
- Pour un Select simple, la ligne est verrouillée PUIS libérée à la lecture,
sauf à préciser USE AND KEEP EXCLUSIVE LOCKS auquel cas elle est verrouillée jusqu'au COMMIT.
- *RR comme *ALL, mais en plus, les autres ne peuvent pas insérer de ligne.
- La transaction est complétement étanche aux autres transactions
et la même requête passée dans la même transaction produit le même résultat (Repeatable Read !)
Synthèse
| Niveau d'isolement réel | NC | UR | CS | RS | RR |
Accès aux lignes en cours de modification ? |
O | O | N | N | N |
Mise à jour des lignes en cours de transaction ? |
N | N | N | N | N |
Le même ordre produit même résultat ? |
N | N | N | N | O |
une ligne mise à jour est modifiable ailleurs? |
O | 1 | 1 | 1 | 1 |
une ligne lue est modifiable ailleurs ? |
2 | 2 | N | N | N |
1 : Non la ligne est verrouillée jusqu'au COMMIT, après Oui bien sûr.
2 : si le curseur est FOR UPDATE Non, sinon Oui
Par ressources, entendez aussi fichiers ouverts !
. première utilisation d'un fichier ou d'une table, il est ouvert puis fermé . dès la deuxième utilisation, il ne sera fermé que suivant ce paramètrevoir SQL_PSEUDO_CLOSE dans QAQQINI sur Knowledge Center. |